One piece of news that hit the headlines this week was the revelation from researchers from the University of Cambridge and Stanford University that Facebook may be a better judge of personalities than spouses or friends. Apart from the obvious hype value this is particularly significant as it shows the power of machine learning in scenarios which we intuitively feel should be difficult for algorithms to handle. Instead it turns out the the inherent lack of subjective bias and prejudice means that given enough data, computers are well placed to make accurate judgements.
Machine Learning: From the preserve of Internet giants to providing insights to the rest of us
Apart from the short-term benefit to Facebook, who can now sell create advertising segments based on user personality in addition to demographics and interests, this is a very topical example of the extent to which user data can be combined with machine learning and predictive analytics to produce powerful insights. Machine learning has long provided the nuts and bolts of the internals of most Internet companies’ operations – e.g. Amazon and Netflix’s recommendation engines, TomTom’s route planning, Facebook’s face recognition, as well as powering spam filters and fraud detection. Now however, this data is being used to provide insights and value to other companies and organisations.
For obvious reasons, one of the applications that gathers most interest is the ability to predict the stock market using search or social data. Recently, researchers from Warwick Business School show how stock market falls follow increased searches on political and economic keywords. Similarly, companies that data mine tweets in the investment community and from insiders at publicly traded companies in order to produce social sentiment analysis and other indicators.
Predictions in the physical world
Machine learning is now expanding beyond our meanderings in the online world to our interactions and location in the physical world, where smartphones apps, fitness bands, navigation devices, as well as sensors and communications nodes such as Beacons and WiFi Hotspots, all generate a very detailed picture of how and where we move in the physical world. Keen to receive some positive publicity, Uber announced that it would be sharing its trip data with the municipal authorities in Boston, to help them in their traffic infrastructure planning (e.g. where to prioritise repairs and new roads) by better understanding traffic flows. In a similar vein, TomTom provides an annual ‘congestion index’ showing how traffic in different cities in the world compare (if you dislike traffic jams, avoid Moscow). This data could be used by municipal authorities as an independent benchmark and measure to how well their traffic management policies are working.

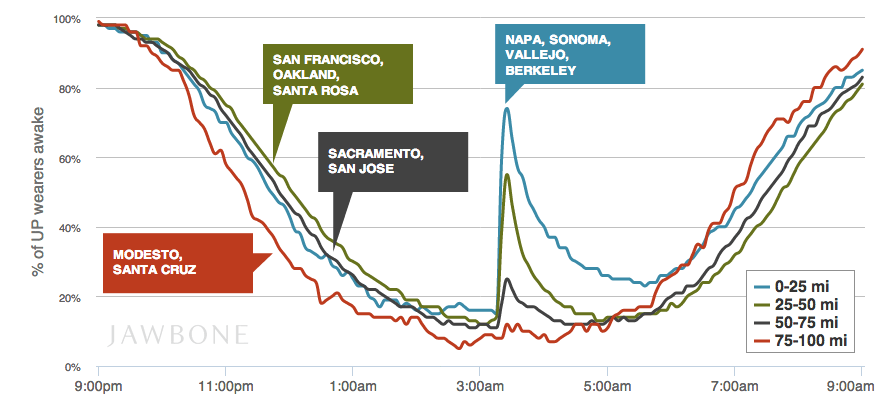
When aggregated across large populations, fitness bands and other wearable devices can provide insights that were otherwise simply not available. For example, Jawbone released data showing the extent to which people’s sleep was disturbed by an earthquake in Napa, California last year. The findings were hardly surprising, showing that the closer one lived to the earthquake, the longer was the interruption to sleep. Jawbone also published data showing in which city people stayed up latest on New Year’s Eve (Moscow, once-again), showing perhaps the more trivial applications to which aggregated personal data can be used.
Notes of caution
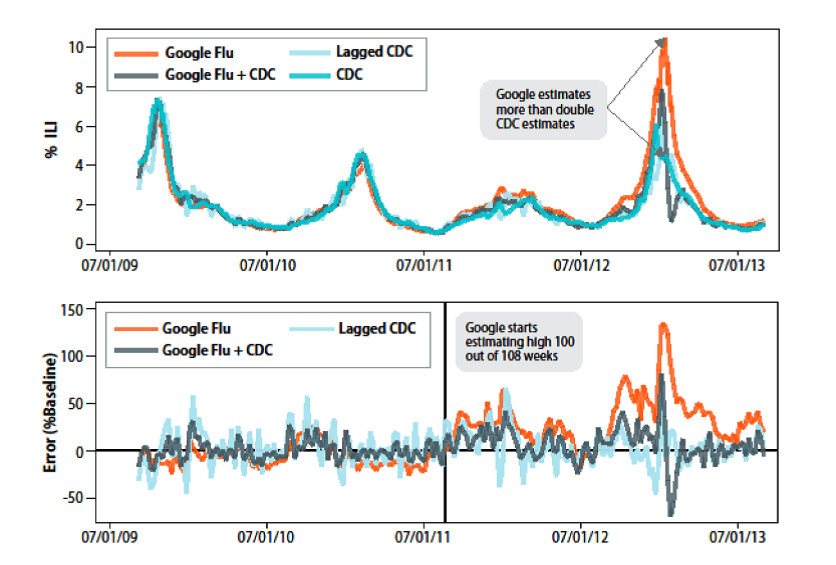
All this must be tempered with some caution as it is way too easy to rely blindly on the reliability of machine-learning predictors and get caught up in big-data hubris. Perhaps one of the most notorious examples of this was the loss of accuracy of Google Flu Trends which once heralded the dawn of an era where machine learning algorithms can replace experts in making predictions. In 2013, Nature reported that for the 12-13 ‘flu season, the Google Flu prediction was more than double the recorded cases, while in 2011-12, it over-estimated flu incidence for 100 out of 108 weeks. This was driven by a number of problems, but largely boiled down to employing a very large data set to find predictors against measured (i.e. actual flu incidence). Although this worked for the first year, modifications to the Google algorithm, user behaviour, and other statistical anomalies, meant that with time the prediction became more and more inaccurate. As Google does not disclose how its search algorithms work, or indeed what the predictors used were, there was no way to have a proper scientific review and improvement of the results.
All this shows that in addition to all the significant privacy concerns discussed last a post last week, data and intelligent algorithms on their own are not a substitute for expert insight. However when used with due caution and understanding, this data will undoubtedly drive a revolution in how we understand and perceive our world and the way we interact with it.