


I vaguely recall reading a few years ago a survey that claimed that engineers believed that Murphy’s law was the fundamental physical law that was most relevant to their profession. Often quoted as, “If something can go wrong, it will,” the engineers surveyed indicated that Murphy’s law was more important to them than, say, Newton’s equations or the laws of thermodynamics. At the time, I took it to be an amusing piece of trivia that said more about the sense of humour of the engineers being questioned than about the engineering discipline. Some years later and hopefully wiser, I have since developed a healthy appreciation for Murphy’s adage.
Some claim that Murphy’s Law has its underpinning in the laws of physics, specifically in the law of thermodynamics, which states that “for isolated systems, the entropy, a measure of disorder, can only increase.” This means that the state of things naturally gravitates from order to disorder. This is why it is possible to break a vase, but not to unbreak it without inputting a lot of energy, effort and patience. Whilst interesting, I believe that the association with the second law of thermodynamics is wrong. Most human-made contraptions, be they as simple as a garden swing, or as complex as a spacecraft, are not isolated systems. They are all localised engineering systems, to which energy is added in order to ensure that entropy is reduced. The answer to why such systems must therefore lie elsewhere.
Failure as a product feature
When applied to systems, be they man-made or otherwise, Murphy’s Law stands as a law in its own right. If it is possible for something to go wrong, then failure is a possible, valid state of the engineering system being created. Given enough time, and a large enough number of inputs, a system or product can occupy all possible states, including those where failure occurs. If something can fail, then it stands to reason that eventually, it will fail. Failure should not be considered as an aberration, a freak or unlucky event, but rather an inherent characteristic of the system as designed.
Although failure is a fundamental characteristic of complex systems, there are different ways in which systems fail. Equally, not all failures have the same impact. Some can be contained, having no or negligible human or economic impact, while others fail with catastrophic consequences, with economic repercussions in hundreds of millions of dollars, impacting millions of people. In this post, I try to cast a light on what makes the difference between failures that hit the headlines and those we don’t even notice.
Failure to test – the loss of Ariane 5
The Ariane 5 is the European Space Agency’s successful heavy lift rocket launcher, used to send payloads of around 10 tonnes into orbit or beyond. It made the headlines on Christmas day 2021 when it successfully dispatched the James Webb space telescope towards its final orbital destination between the sun and Earth. However, the start of Ariane 5 program was not particularly auspicious. On 4 June 1996, 37 seconds into its maiden flight from its launchpad in French Guiana, the rocket started to veer off its intended flight path before self-destructing by its flight termination system.

The loss of flight V88 has been described as one of the most expensive software bugs in history. The investigation report into the loss of flight V88 found that the system for measuring the rocket’s position and motion, known as the Inertial Reference System (SRI) failed after 37 seconds. This was caused by an arithmetic overflow when a 64-bit floating point number couldn’t be accommodated by a 16-bit integer. (Don’t worry, I won’t mention number systems any further.)
How could such a number formatting issue result in such a catastrophic failure? Ariane 5 did, in fact, have two independent SRI systems. However, as these were to protect primarily against hardware failure, they ran identical software. When one failed due to a design error (i.e. a bug), then the other failed at the same time for the same reason. Any software engineer would then ask why wasn’t this bug picked up in testing. Surely such mission-critical software must meet exacting quality standards? It turned out that although the software function that failed served no purpose once the rocket left the launch pad, it was left running. Moreover, as this was carry-over software from Ariane 4, the previous generation of rocket, it was considered as highly reliable. However, the Ariane 5 trajectory was significantly different from that of Ariane 4, so this software was running considerably outside the operating envelope it was tested for. The bug caused the arithmetic overflow when following a valid Ariane 5 trajectory, but not in the Ariane 4 flight envelope, which is for which it had been tested. The rather startling conclusion of the board of enquiry was that the software simply hadn’t been tested within the flight parameters of the Ariane 5 rocket.
Worrying about the wrong problem – United Flight 173
In his rather excellent book Team of Teams, Gen. Stanley McChrystal tells the unfortunate story of United flight 173 heading to Portland, Oregon from New York on 28 December 1978. On approaching its destination at 5:00 pm, the landing gear was lowered, resulting in a loud thud. An indicator light that should signal a successful deployment of the landing gear failed to illuminate. The landing was immediately aborted, and the captain led the crew in planning for a rough landing. Although the control tower confirmed that the landing gear had in fact appeared to deploy correctly, the crew worked their way through their preparations, including how to exit the plane, what to do after they have landed, and even tidying up the cockpit. So focused were they on running through the entire checklist of dealing with the aftermath of an emergency landing, that they forgot their number one priority – to keep the aircraft flying. After 70 minutes, they ran out of fuel, and crash landed six miles away from the destination, suffering ten fatalities.
The US crash investigators determined that the captain, in line with common practice at the time, had adopted a command and control approach to managing the incident, issuing instructions to the crew and communicating with the control tower. His crew, in return, took their guidance and instruction entirely from their captain. Therefore, as the captain was completely focused on the entirely survivable landing gear issue, so was the rest of the crew. His fixation on a non-critical problem created a blind spot that the crew could not uncover. The captain, as the only empowered decision-maker, ignored an immeasurably more critical issue that threatened the safety of all passengers and crew.
In this case, the crew were not a team, empowered to share the cognitive challenge of landing the plane safely. In the aftermath of this failure, United Airlines, and most of the airline industry revamped their pilot training to improve communications between crew members and share the cognitive load in order to make better decisions in emergencies.
The single point of failure – Facebook disappears from the Internet
The online services that we use every day from our smartphones and computers, be they searching the web on Google, buying goods on Amazon, or chatting to your friends on your favourite social network, all rely on large-scale distributed computer systems, referred to simply, as ‘the cloud.’ Each large tech company has its own ‘cloud’ consisting of data centres across the world (Google, for example, states to have 103 zones), each hosting thousands of servers, and connected to each other by their own private fibre networks. The largest applications are in fact comprised of hundreds of smaller applications, that are often interconnected and distributed across the cloud infrastructure. Although their scale is less visible than, say a large naval vessel, these systems constitute some of the most complex engineering undertakings today.
On 4 October 2021, Facebook stopped working world-wide. It was as though ‘it disappeared from the Internet.’ For five hours that day, Internet service providers across the world were unable to connect to Facebook, meaning that the service was inaccessible to its users. In a blog post published the day after the outage, Facebook explained how it relies on a backbone network to connect its data centres to each other and to the Internet. A command issued as part of its routine maintenance procedures unintentionally caused a complete disconnection of this backbone network. In turn, the DNS services which are used to convert facebook.com to individual Facebook server addresses were automatically disconnected, as they were no longer able to talk to the Facebook servers. This made it impossible for the rest of the internet to find Facebook. To make matters worse, most of the tools, that Facebook engineers use to debug and fix problems were now also out of action as they used the same backbone network was down. Engineers needed to physically go to each of the data centres and restart systems from there. As data centres are designed with high levels of physical security, engineers struggled to gain access to the hardware required to fix the problem.
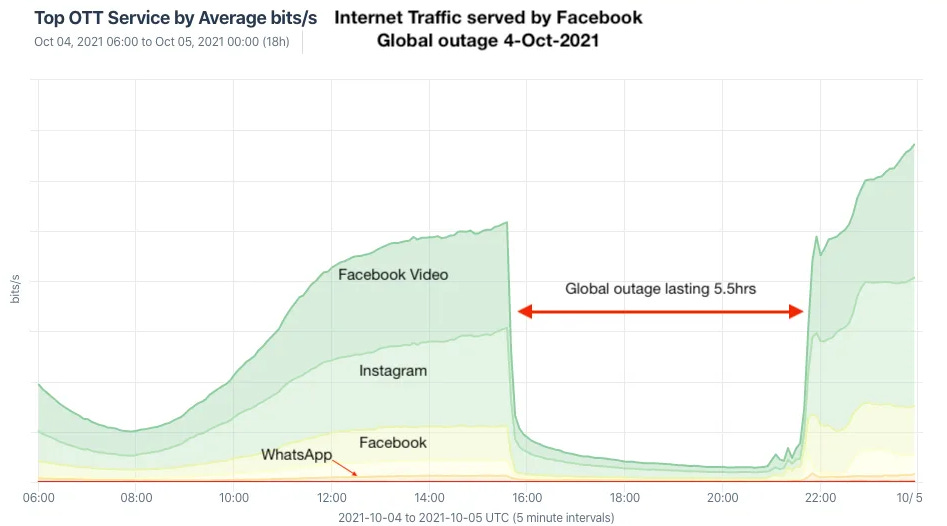
Despite having apparently well-drilled plans for dealing with failures of individual services, and tests to ensure that changes are safe, a bug in the systems that check for the safety of maintenance jobs failed to stop the incorrectly formed command from being run. Whilst it is tempted to focus on this as the root cause of this failure, the Facebook outage is a classic example of a single highly complex system being vulnerable to a single point of failure. Much like the Death Star in Star Wars which was destroyed when the Rebel ships shot directly at the reactor core, Facebook, and all its customer-facing services and internal tools were dependent on the system that manages their global backbone network. When that system failed, there was no failover capability to take over, and Facebook simply stopped working.
Silos – Left hand not knowing what the right hand is doing
On 23 September 1999, NASA engineers in mission control were observing the last stages of re-entry of the Mars Climate Orbiter, a spacecraft which was in the last final few minutes of a 10-month journey to Mars. Communications with the spacecraft were lost, and it slowly dawned on the assembled team that they would not be celebrating the culmination of a multi-year project, but instead try to figure out why the craft was lost on re-entry. The mission planners had intended for the probe to enter the Martian atmosphere within a given altitude, a Goldilocks zone where the atmospheric density was high enough to slow it down, but not damage it.
It turns out that rather than entering the atmosphere 110km above the surface, the spacecraft entered around 57 km, in a denser-than-expected atmosphere, causing it either to be destroyed or to bounce off, damaged into space. Post-failure investigations exposed that one piece of software, supplied by Lockheed Martin, a NASA contractor, produced results in Imperial Units of measurements, while a second system, designed in-house at NASA’s Jet Propulsion Laboratory, used the metric system. A NASA review board determined that the software that controlled the orbiter’s thrusters calculated the force in pounds, while NASA’s software assumed it was the equivalent metric unit, newtons per square meter. Two different teams were in effect working to different, incompatible standards, and although the contracting documentation did require Lockheed Martin to ensure that the interface to other systems used metric units, NASA failed to make th necessary checks and tests to ensure that the system worked.

This is a very common failure scenario, where different parts of a project team fail to recognise that their constituent parts are incompatible, perhaps making incorrect assumptions, misinterpreting specification documents, or simply, as in this case, not designed to an intended specification. There are a whole host of mechanisms that can be used to prevent such issues from the catastrophic consequences suffered by the Mars Climate Orbiter, most of which involve a combination of verifying the intended designs, and testing that the integrated system works well. What was ironic in this case, is that NASA practically invented modern Systems Engineering in order to deliver the Apollo moon programme. An often inefficient approach, this requires project teams, to methodically and exhaustively decompose systems into progressively smaller systems with all functionality and interfaces between components comprehensively documented in advance. Had NASA followed its own practices (see its 275 page handbook here), then this accident would have been avoided.
Failure Cascade – America’s largest Blackout
Given that complex systems are interconnected networks of smaller components or subsystems, the impact of a failure of a component on other connected components is a crucial consideration in understanding how robust that system is to failure. Failure propagation occurs when a failure in one part of the system leads to other failures in other parts of the system, which in turn can propagate onwards. For example, the human body is an interdependent system that relies on all organs and physiologic systems working well. For example, a failure in the circulatory system can quickly impact the brain and nervous system, in turn causing failures to other organs.
When power grids and distributed computing systems (e.g. cloud platforms) often fail due to cascading failures. Typically, one relatively small part of the system fails, causing the load to be shifted to other, healthy parts of the system. In the case of power grids, this load consists of electric current, while for distributed computing systems, this will be computing load to service (for example) customer applications. This shifting of traffic is often required to maintain healthy operation, bypassing failed components, but can sometimes be the driver of catastrophic failure.
On 14 August 2003, a high-voltage power line in Ohio, USA brushed against some overgrown trees and shut it down. Normally, this would trip an alarm in the control room of FirstEnergy Corporation, the energy company operating that part of the grid, but the alarm failed. Over the next hour and a half, other lines sagged as the increased load heated them up. This caused them to soften and sag into trees. These were automatically disconnected, in turn shifting the load to yet other power lines, which had to carry even more load. Two hours after the original failure, the entire segment of the power grid failed and switched off, triggering a cascade of failure across much of north-east USA and southeastern Canada.
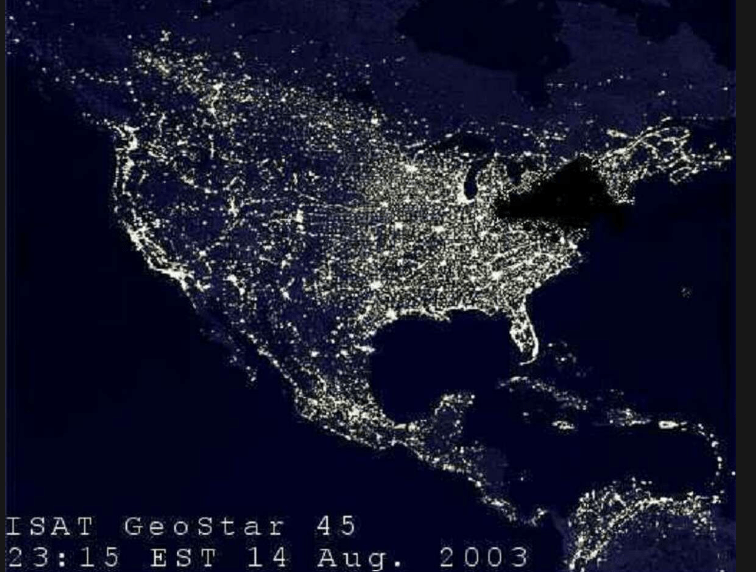
50 million people lost power for up to two days in the biggest power blackout in American history. This was a classic case of failure propagation with positive feedback. What should have been an isolated failure instead resulted in a progressive shifting of increasing load levels on those parts of the grid that remained in operation, driving a very wide-scale failure. A lack of instrumentation meant that FirstEnergy’s technical staff were unable to identify what was happening and isolate the problem while it still could be contained. Like in an avalanche, it took a relatively small movement to trigger a much larger event.
Misunderstanding the Problem – A wobbly bridge
June 2000 saw the opening of the first new pedestrian bridge across the Thames in London for over 100 years, when to the consternation of its designers, the bridge began to sway to the extent that it was called ‘the wobbly bridge’ by Londoners. Initially, the bridge’s architects said that it was designed to have some movement as it was a suspension bridge, but pedestrians were unimpressed. “I think you need to take your sea sickness pills before crossing,” said a woman after crossing the bridge. Although initial theories focused on pedestrians walking in synchronicity, amplifying any slight wobble until it started swaying to an uncomfortable extent, more recent studies showed that this was not the case. In fact, walkers were compensating for slight wobbles by adjusting their gait, so as to keep stable. This caused a positive feedback effect that amplified any sideways wobble, even before they started to walk in synchronicity.

Although the bridge’s designers applied the commonly-established standards of the time and presumably modelled the design accordingly, they simply didn’t understand the interaction between the bridge and pedestrians. The knowledge of the biomechanics of how people adjust their stride to retain their balance and the consequent interaction with swaying platforms did not exist until a retrospective study was published in Nature magazine half a decade later. The models used by the designers simply did not reflect the forces the bridge would experience in real-world use.
Conclusion
In this post, I have aimed to take a relative broad look at how human-made systems fail. While this is nowhere near being a comprehensive analysis, hopefully, the diversity of examples used gives a sense of the fundamental systems-level concepts at play that transcends the actual application or system. Although the component-level failure is often technology-specific, be it the failure to trap a software exception or the material properties of the infamous Space Shuttle booster rockets’ O-rings at low temperature, it is systems-level design that makes the difference between a catastrophic failure and a mere blip.
Further Reading
ESA, Ariane 501 – Presentation of Inquiry Board report, July 1996
Engineering at Meta – More details about the October 4 outage
Valdez et al, Cascading Failures in Complex Networks, Journal of Complex Networks
Minkel, The 2003 Blackout – Ten Years Later, Scientific American, 2008
New study sheds more light on what caused Millennium Bridge to wobble
The post Why things break appeared first on The Sand Reckoner.